中国的生成式 AI 有多强?《经济学人》剖析中美差距
Foresight · 2023-06-14 11:32
Meta
OpenAI
META
《经济学人》杂志认为,目前中国的大模型落后于美国两到三年,原因在于两国在训练数据、芯片等硬件及科技人才上的距离。
来源:《经济学人》杂志
编译:凯蒂
从百度的文心一言开始,生成式 AI 成为中国的互联网及科技公司进发的新高地,阿里巴巴的通义千问、腾讯的混元、华为的盘古、科大讯飞的星火到昨天 360 发布智脑,国产的生成式 AI 产品频繁曝光,AI 在国内已经俨然科技新风口,也在海外引发关注。
「中国在生成式 AI 上有多强?」这是近日英国时政杂志《经济学人》发文的标题。文章从论文数、系统数、算力和芯片硬件几个基础层面的 4 张图表,比对了两国的实力。文章认为,目前中国的大模型落后于美国两到三年,原因在于两国在训练数据、芯片等硬件及科技人才上的距离。
文章也指出,这些差距都有各自的解决方式,最终,差距不会太大,而美国真正的优势地带是将技术高效应用和扩散的能力。以下为这篇《经济学人》文章的编译节选:
从北京和华盛顿唱的高调来看,中国和美国正在全力投入一场争夺科技霸主的较量。
「从根本上说,我们相信少数几项技术将在未来十年发挥极其重要的作用。」美国总统拜登的国家安全顾问杰克·沙利文 (Jake Sullivan) 去年 9 月这样说。今年 2 月,中国领导人同样呼应了这一观点称「我们迫切需要加强基础研究,从源头和底层解决关键的技术问题」,以「应对国际科技竞争、实现高水平的自立自强」。
当下,没有哪项技术比人工智能 (AI) 更能吸引太平洋两岸决策者的关注。ChatGPT 等生成式 AI 能力的迅速提升,愈发加强了这种关注。这类大模型分析网络上所有的文本、图像或声音,然后创造出越来越真实的仿造物。
如果生成式 AI 真的像其支持者说的那样具有革命性,那么善于运用它的国家就可能在 21 世纪重要的地缘政治竞争中获得经济和军事上的优势。西方和中国的战略家已经在讨论 AI 军备竞赛。这场竞赛中,中国能赢吗?
过去几年,中国在某些衡量 AI 实力的指标上领先于美国。2019 年,中国的 AI 论文占比超过了美国。2021 年,全球 26% 的 AI 论文来自中国,而来自美国的占比只有 17%。按 AI 论文发表量计算,全球排名前十的机构中有九个在中国。根据一个常用的基准,计算机视觉领域排名前五的实验室也都在中国。
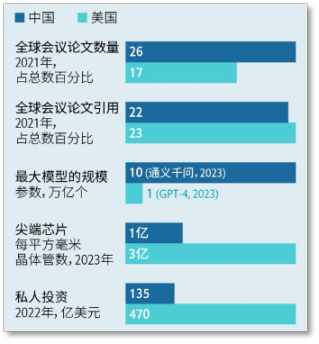 中美 AI 相关指标的对比
中美 AI 相关指标的对比
然而,在「基础模型」这种赋予生成式 AI 智慧的领域,美国的优势明显。
ChatGPT 及其背后先进的模型 ( 最新版本为 GPT-4) 是美国创业公司 OpenAI 研发的。其他美国公司也有自己强大的系统,其中既有 Anthropic 或 StabilityAI 等小公司,也有谷歌、Meta 和微软 ( 持有部分 OpenAI 股份 ) 等科技巨头。文心一言是中国互联网搜索巨头百度打造的对标 ChatGPT 的产品,人们普遍认为它的智能程度没有 ChatGPT 高。
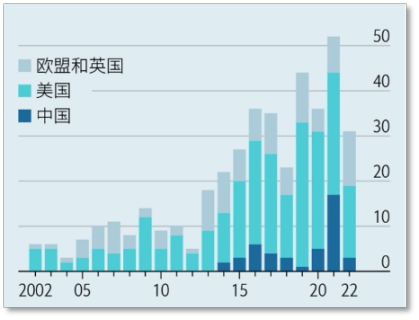
中国、美国、欧洲的机器学习系统的数量对比
这使业内人士得出了这样的结论:中国在建立基础模型方面比美国落后两到三年。
造成这一差距的原因有三个。第一个原因涉及数据。例如,商汤科技、旷视科技等 AI 公司获得来自政府部门的数据后,在其领先的计算机视觉实验室的帮助下开发出了一流的面部识别系统。这项优势到了生成式 AI 上却没有那么强大了,因为基础模型是用网络上大量的非结构化数据训练的。
根据互联网研究网站 W3Techs 的数据,全球 56% 的网站是英文的,而只有 1.5% 的网站是中文的,这有利于美国的建模者。
斯坦福大学的傅亦沁博士指出,中国人主要是通过微信和微博等 App 上网互动。这些 App 属于「围墙内的花园」,其中大部分内容都没有在搜索引擎上建立索引。这让 AI 模型在训练时难以吸收这些内容。例如,北京智源人工智能研究院于 2021 年推出的模型「悟道 2.0」尽管在计算层面上有可能比 GPT-4 更复杂,但未能引起轰动,缺乏数据也许是一个原因。
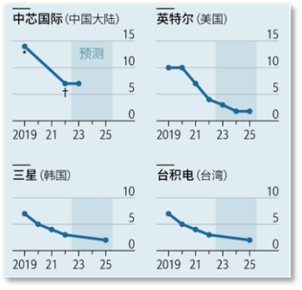
各大半导体公司的芯片生产能力
中国在生成式 AI 上的表现平平的第二个原因与硬件有关。去年,美国对一些 AI 领域的关键技术实施了面向中国的出口管制,其中包括云计算数据中心 ( 基础模型在其中学习 ) 所用的微处理器,以及可以让中国自行制造此类半导体的芯片制造工具。
这打击了中国的大模型研发。英国智库 AI 治理中心分析了 26 个中国大模型后发现,超过一半的模型的芯片都要依赖美国芯片公司英伟达。一些报告表明,中国最大的芯片制造商中芯国际的产品只比行业领导者台积电晚一两代,但中芯国际目前只能大规模生产台积电在三四年前就量产了的芯片。
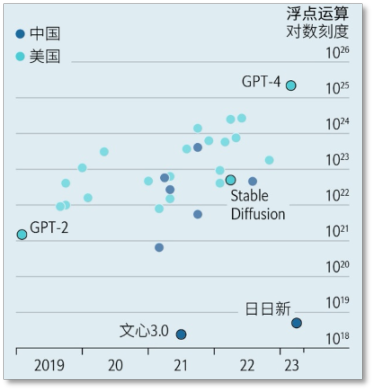
另一样中国 AI 公司难以从美国引入的东西是人才。目前,美国对全球科技人才仍然极具吸引力:在期刊上发布论文的美国 AI 专家中有三分之二在国外出生。2019 年,华裔工程师占到这个顶尖群体的 27%。许多中国的 AI 研究人员曾在美国学习或工作,然后带着专业知识回国。不过,新冠疫情和中美关系紧张加剧导致这一群体的人数下降。2022 年上半年,美国向中国学生发放的签证数量是 2019 年同期的一半。
数据、硬件和人才的三重短缺对中国的 AI 发展造成了障碍,但这些因素是否会在更长时间内阻碍中国的 AI 雄心则是另一回事。
先说数据问题。今年 2 月,在聚集了中国近三分之一 AI 公司的北京,当地政府承诺开放 115 个政府下属单位的数据,为建模机构提供 15880 个数据集。前美国驻华外交官,现就职于牛津大学的凯拉·布洛姆奎斯特 (Kayla Blomquist) 表示,中国政府此前曾表示希望拆除中国 App 的围墙,这样可能会释放出更多数据。
另外,近期这批大火的生成式大模型能够将机器学习的成果从一种语言转换为到另一种语言。OpenAI 表示,尽管在训练数据中缺乏中文材料,但 GPT-4 在中文任务上的表现非常出色。乔治华盛顿大学的杰弗里丁 (Jeffrey Ding) 指出,百度的文心接受了大量英语数据的训练。
在硬件方面,中国也在寻找变通办法。英国《金融时报》3 月报道称,被美国列入黑名单的商汤科技利用了中间商规避出口管制。另一些中国 AI 公司正通过位于其他国家的云服务器使用英伟达的芯片。还有一个办法是购买更多英伟达不太先进的产品。为了继续服务广大的中国市场,英伟达设计了符合制裁规定的产品,这些产品的速度比顶级产品慢 10% 到 30%。对于中国客户来说,这增加了处理能力的成本,但至少还够用。
中国还可以用开源模型让缺乏芯片和人才的问题得到一定程度的缓解。任何人都可以下载开源模型的内在工作机制,并针对特定任务进行微调。这当中包括了模型参数,这些数字决定了模型的结构,是经由成本高昂的大量训练得出的。斯坦福大学的研究人员使用 Meta 的基础模型 LLaMA 的参数构建了一个名为 Alpaca 的模型,成本不到 600 美元,而训练 GPT-4 这样的模型可能需要 1 亿美元。Alpaca 在某些任务上的表现不逊于 ChatGPT 的最初版本。
考虑到上述因素,很难想象美国或中国能够在 AI 大模型方面建立不可逾越的领先优势。两国可能最终将拥有能力类似的 AI,即使中国在过程中会因为美国的制裁而付出额外代价。但是,如果大模型的竞争势均力敌,那么美国的另一个优势有可能让它成为 AI 大赢家,那就是它有能力在经济体系中广泛应用其尖端科技。历史上,正是新技术在大范围内的高效应用帮助美国在与苏联的科技竞赛中取得领先,尽管苏联在上世纪 50 年代培养的理科博士数量是美国的两倍。
中国远比苏联善于应用新科技。它的金融科技平台、5G 电信和高铁都是世界一流的。尽管如此,杰弗里·丁表示,这些成功可能只是例外,而不是常态,尤其是中国在部署云计算和商业软件方面的表现没那么出色,而这两者都是 AI 的配套设施。
尽管美国的出口管制可能并不会阻碍中国所有的大模型进展,但会在更广的范围里限制中国的科技产业,从而减缓对新科技的采用。比如,中国企业整体而言缺乏积极推动新技术扩散的技术专家,以及资金流向 AI 行业的不确定性。去年,对中国 AI 创业公司的私人投资为 135 亿美元,不到流向美国竞争对手的资金的三分之一。据数据供应商 PitchBook 称,在 2023 年的前四个月,这一投资的差距似乎又进一步扩大了。
无论生成式 AI 是否真的具有革命性,自由市场已经把赌注押在能充分利用它的玩家身上。
免责声明:
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表Bi123的观点或立场



