Web3 青年学者计划:除了找漏洞,形式化验证还有哪些作用?
Foresight · 2023-07-14 14:10
NFT
Web3
Flow
形式化验证除了找漏洞,还可以进行代币检测、套利和链上攻击防御。
嘉宾:Chaofan Shou,UC Berkeley 博士
整理:aididiaojp.eth,Foresight News
本文为 Web3 青年学者计划中 UC Berkeley 博士 Chaofan Shou 视频分享的文字整理。Web3 青年学者计划由 DRK Lab 联合 imToken 和 Crytape 共同发起,会邀请加密领域中知名的青年学者面向华语社区分享一些最新的研究成果。

大家好,我是 UC Berkeley 博士研究生在读的 Chaofan Shou,主要研究方向是程序分析和软件安全。今天我会分享除了找漏洞,形式化验证有哪些用途?首先会先介绍一下形式化验证的原理和作用,进而分享一些形式化验证的新应用,比如说自动化套利,或者自动化代币分析和链上攻击预测和生成。所有的这些应用我们都发现形式化验证的运行效率低下,不足以很好地支持这些应用。在此基础上,我们开发了一些新方案来加速形式化验证,最后会聊一下形式化验证和大语言模型之间的关系。

形式化验证有两个作用,第一个作用是验证程序是否会按照某一个规范执行,第二个作用是为程序生成所有的测试用例,以达到 100% 的测试覆盖率。形式化验证的流程就是给定一个代码和一个规范,规范也可以没有,我们会把这两个东西转换成一个数学的表达式,我们用定理证明器去验证这个数学公式是否能返回真。如果不能,到底输入什么能导致数学公式成立?

这是一个比较简单的例子,左边是一个部署在合约中的函数,它主要的作用是你可以通过支付一定的 ETH 来猜一个数字,而这个数字会被设置到合约状态当中。我们可以把这一个代码简单地转换成控制流的图。这个图有两个结果,一个是状态改变,一种是还原状态。有了这个流程图,我们就可以生成出来达到两个目标的条件。比如说如果我们要状态改变的话,条件是交易的价值是十,我的数字是小于等于十,且大于等于一。形式化验证需要具体的数字输入,在这里就是 message value 和 number 这两个数值能让条件成立。比如说这里能让条件成立的是 message value 等于十,number 然后等于一。还有一种情况,它会返还初始值。有这个测试用例,我们就可以覆盖整个程序,这是形式化验证的第一个作用。

第二个作用是我们可以验证程序是不是符合某一个规范。首先我们需要先把控制流程图转换成一个数学表达式。这些条件我们用与条件连接在一起,我们可以用这里的这一串表达式表示出整个程序。造成的影响就是这些状态会改变,如果不符合,我就会返还初始值。这两个条件它各自都是 True 的,不管 message value 或者 number 是什么数字,这两个条件都是永远是真的,所以我整输出的结果也都是真的,这就是形式化验证,可以随机审核,没有特定的数值,没有特定的条件,它可以直接输出任意满足条件的数字。
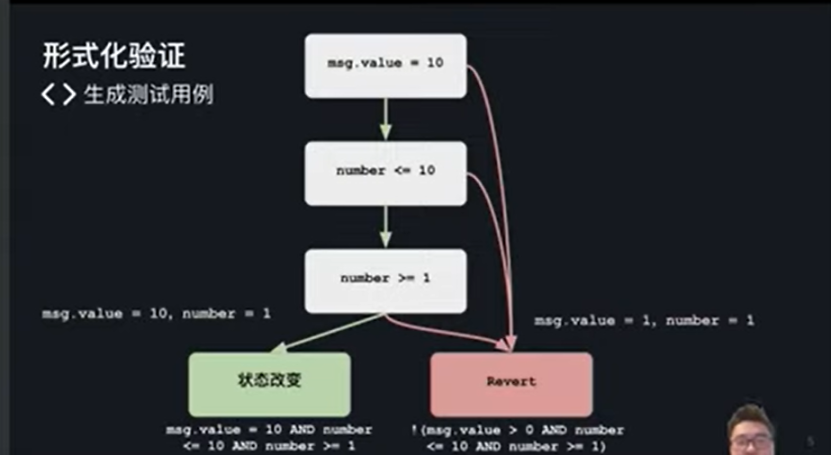
规范描述了合约是如何运行的。如上图例子,不管是什么什么情况下,这里 bet 的数值永远是小于十的。用正式规范表示出来就是类似于这样,但其实这个是错的,因为我们的 number 小于等于十,而不是小于十。所以说当我的 number 是等于十的时候,其实这个规范就会被违反,正确的规范是 bet 永远小于或等于十。我们怎么把规范和之前的数学表达式结合在一起呢,我们直接把它加入到之前的数学表达式就可以了。合并在一起之后,就可以通过形式化的验证去确定它是不是会违反规范,但是目前来看,其实验形式化验证会生成 bet 小于十的情况下 Messagevalue 和 number 的数值,而不是真正我们要想找的违反规范的输入。如果我们要找违反规范的输入,我们要用否定条件把这这些条件包含在内,如果这个条件成立的话,message value 和 number 是什么?整个流程成立的话,就说明给定这个程序,我们违反这一个规范。

一个很简单的模型是我的 message value 等于十,number 是一,数学公式返回的结果就是 true。这里我们是可以直接用手算出来的,但是真实的情况下,其实程序会非常复杂,比如说大部分情况下这些条件会类似于这样。所以我们需要用到定理验证器,相当于说我们把之前人工的步骤让电脑去计算。定理验证器简单来说是给定数学公式,它能告诉你哪一个模型或者哪输入能让这个条件为真。

我刚才举的这个例子在合约里面就只执行了一次,也就是只能验证在一个交易之后,这个合约是不是会遵守这个规范,或者说我只能在测试用例中生成单个交易。所以更复杂的形式化验证用在合约或者别的有状态的软件领域当中,我们管这个规范叫做线性持续规范就是 LTL,它可以考虑时间因素,比如说系统在未来某个时间点会发生什么,系统始终会满足哪一个条件?像我们刚才那样,比如说我们可以说 total bet 是永远小于 1000 的。如果是单个交易的话,total bets 确实是会小于 1000,因为你一次最多只能加十,但是如果是下面这个条件,total bets 都是小于 1000,那这是会被违反的。因为当你有 100 个这样的交易之后,其实你的 total bats 就已经是大于等于 1000 了。这就是线性持续规范和普通规范的区别。我们可以用同样的方式去验证程序是否会符合某一个线性持续规范。

形式化验证是一个生成测试用例的手段,同时可以去验证程序是不是会违反某一个规范,如果违反的话,它具体的输入是什么?或者说它具体的交易是什么?

形式化验证的第一个应用是套利。常规的套利大家都应该比较熟悉,目前链上有很多可以自动识别价差,或者说交易对中不平衡的状态,它就可以非常快速的进行套利。现在链上有非常多这样的套利机器人。如果我们做常规套利的话,在链上是不会获利的。

但是对于非常规套利来说,目前我还没有见到任何的机器人能做到这一点。举个例子,比如代币可能在合约中有预售,这个合约你没办法直接按照某种规范或者数学模型去模拟,你需要进行手动分析才能知道。我在合约中预售的价格和 Uniswap 上的价格存在价差,这样的话我们可以先在合约中的预售买入大量的代币,然后再在 Uniswap 上抛掉,这样的话我们可以利用这个价差获利。

第二种情况就是在一些比较复杂的 NFT 借贷平台,当 NFT 价格波动比较大的情况下,我们可以直接生成交易来清算某些用户的 NFT 进而从中获利。但是如果你手工创建这些交易的话,需要一个非常复杂的过程。如果你能用形式化验证直接生成出来这些交易的话,可以在非常短的时间内自动化找到这些套利机会。
形式化验证唯一需要的规范就是收入大于或等于支出。具体的流程是把未知的合约先转换为数学表达式,然后我们会对已知合约进行数学建模,去看是否能让形式化验证生成使收入大于支出的交易。
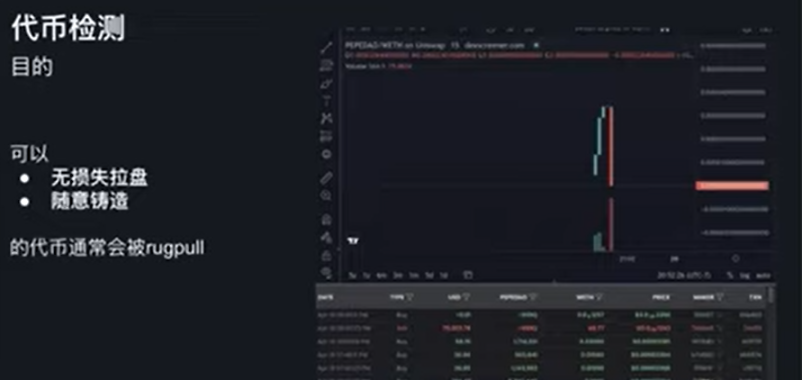
第二个应用是代币检测。很多交易者都会去买一些新上市的 ERC-20 代币,因为任何人都可以在链上创建 ERC-20 代币,所以你需要判断 ERC-20 合约是不是真的。比如说我可以无损失拉盘,换句话说我可以让我的代币一直涨,你买了之后你是没办法卖出的,所以说我不断的涨,你仍然没办法获利。我可以从很低的价格一直涨到很高的价格吸引很多的投资者,但是没有一个投资者可以卖出这个代币。这种无损失拉盘的代币通常会卷钱跑路。还有一种比如说可以随意铸造代币,这样可以增发的代币通常被 Rug。上图就是一个 Rug 的代币,它可以在很短的时间内涨幅达到几万倍,然后又在很短的时间内归零。
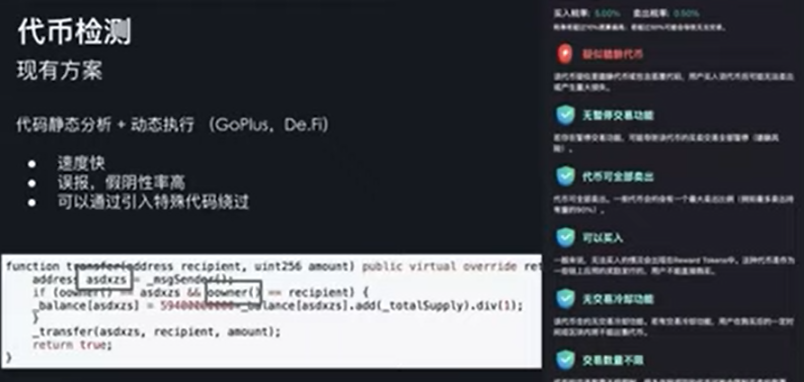
现有的代币检测方案有像 GoPlus 和 De.Fi 采用的是代码相似度、静态分析和动态执行去检测代币是不是存在风险。这种方法的好处就是它的速度非常快,你可以在几毫秒内就完成整一个分析,但是它的缺点就是误报率非常高,它的假阴性率非常高。像下面这个例子骗子可以通过加入一些代码,并引入一些奇怪的变量名绕过整个检测。直接用代码相似度、静态分析或者动态执行,其实是没办法很好的检测代币是否会存在风险。

形式化验证和静态分析不太一样。静态分析相当于你有一个程序,你要做的事情就是分析这个程序是不是有类似的代码或者类似控制流。形式化验证更多的是你定义一个结果,而不是看这个执行的过程。你直接看这个结果是不是会成立,比如我们要检测它是否可以增发,静态检测的话,这里这个条件会成立,但是因为它加入了这一行代码,就会破坏整个静态检测,因为静态检测库是没有类似路径或者类似模式。如果用形式化验证的话,我们直接就可以定义规范,总的代币发行量是恒定的。对于 ERC-20 代币来说,我们就可以用定理验证器生成模型。

第二个例子是我可以检测这个代币是否存在黑名单。如果存在黑名单的话,可能没办法交易。发币者可以封禁任何的账户。通常来说。静态检测很难发现,因为如果它在这里插入了一个特定代码,相似度分析就会失效,又因为它用了这些名字,静态分析和代码相似度两个检测都会失效。动态分析也是没办法执行到这行代码。但是如果我们用形式化验证的话,我们就可以定一个规范,比如说我在调用了 transfer2K 之后,账户一定会收到 K 个代币。我们就可以用定理验证器去生成出来具体的模型。使用这个方法相当于把 M 这个账户拉黑了,然后 M 在调用这个 transfer 之后,它就会失败,因为这一行代码它可以把这个数量全部减为零。
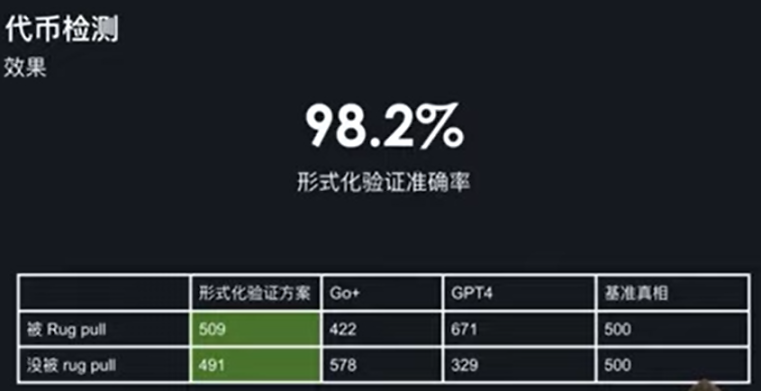
这是我们代币检测的效果,就是我们显示化验证的准确率是能达到 98.2% 的。我们收集了 1000 个代币,其中 500 个已经是被人家卷钱跑路了,被 Rug Pull 了,还有 500 个没有被 Rug Pull。形式化验证方案能将 509 个代币准确的归类到被 Rug Pull 的这一类,然后 491 个归类到没有被 Rug Pull 的这一类,相比于其他方案准确率是较高的。

另外一个新应用是链上的攻击,预测和生成。大家应该都知道在 3 月的时候 ParaSpace 被黑,BlockSec 通过抢跑这攻击的交,然后一共拯救了 500 多万美元。BlockSec 具体是怎么做到的呢,接下来会介绍整个常规攻击防御流程。当黑客提交攻击交易的时候,他会发到一个节点,这个节点可能是验证节点,也可能就是一个普通的节点。然后会进入到这个节点的交易池,当进入到一个节点的交易池,这个节点就会去广播这个交易。如果你是防守方,你可以去监听这个广播,然后你也可以收到这个攻击交易。相当于说防守方可以实时监听交易池中的交易。当防守方拿到这个交易的时候,就可以对这个交易进行分析,然后将里面的地址改一下,看看是不是还可以赚钱。如果还可以的话,就生成出来一个新的交易,相当于修改攻击,然后再广播到所有的验证节点上面去。
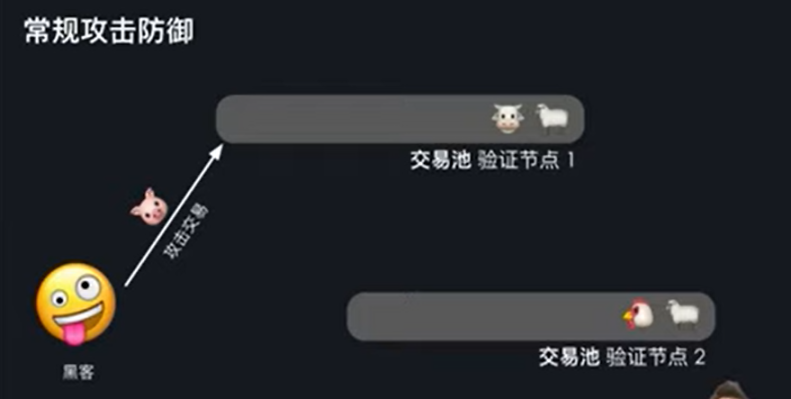
如果防御交易是在攻击交易前面,就是说防御交易先被执行,然后攻击交易后被执行,这种情况下相当于就是防守方成功了,他先偷到了资产,让黑客没有资金可以去偷。

具体交易是怎么排序的呢?在 Proof of Work 的时候,这个还是比较简单的。你可以通过付更高的 Gas 费来让你的交易放在更前面,你只要把 Gas 费设置为攻击交易的 10 倍,你肯定能成功。但是现在 Proof of Stake 有很大的改变,相当于引入了一个新的概念,叫做 MEV,简单来说你可以通过贿赂一些验证节点,然后决定区块中部分交易的顺序。89% 的以太坊上的区块和 55% 币安链上的区块都是支持。MEV 的具体流程是你提交一个 Bundle,这个 Bundle 相当于一系列的交易,可以是单个,也可以是多个。然后任何人都不可以在这个 Bundle 中插入交易或者修改 Bundle 中的交易。然后这个 Bundle 会被提交到一个新的角色构建者当中。构建者的目标是在考虑到所有的这些 Bundle 和所有的交易之后,构造出最赚钱的区块。当它构造出这个区块之后,它会发给验证节点,让验证节点去提出这个区块。验证节点就不再需要去考虑构建这些区块怎么让自己的利益最大化,因为它可以直接使用最赚钱的区块。

MEV 可以很好的解决之前的防御问题。我可以提交一个 Bundle,这个 Bundle 把我们的防御交易和黑客的攻击交易放在在一起,我们的防御交易就一定会被先执行,黑客的交易会被后执行。MEV 也是一个双刃剑,因为 MEV 支持了隐私交易,就是说黑客可以提交一个交易到构建者。构建者可以选择不广播交易,而是直接创建这个区块,然后创建完这个区块之后发送给这些验证节点。防守方是完全没办法在区块确认前收到这个交易的,而当防守方看到这个攻击交易的时候,攻击交易已经是成功执行了。

这是我们统计的隐私交易和攻击之间的关系。6 月份的时候,我们统计了两周的所有在币安链上的,大概 83% 的攻击都是隐私交易。我们没办法防住这 83% 的攻击。
我们需要改变方法,不在黑客发起攻击的时候防御,而是在黑客准备攻击工作的时候去做防御。比如说黑客刚部署一些攻击合约或者黑客进行一些测试交互,我们就直接对它进行防御,这样的话我们可以有大量的时间去准备这个防御,然后抢跑这个攻击。通常准备工作到发起攻击之间,目前有 30 多秒到几个小时甚至几天。我们先看黑客注入资金。如果他注入的资金方式通过一些比较差的交易所或者说通过 Tornado Cash 隐私混比器,我们会判定它存在比较高的风险,我们会实时监控高风险账户进行的链上交易。
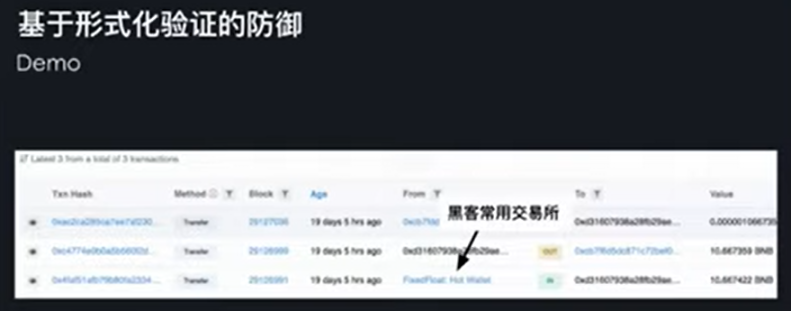
上图是一个例子,在十几天前,我们看到一个账户收到了一笔资金,从一个比较有名的黑客常用的交易所转入。然后他创建了攻击交易在 29154741 这个区块,在十个区块之后 30 秒之后攻击发生。我们能干的事就是在这十个区块 30 秒内,我们分析完这整个攻击合约,然后生成出来整个具体攻击。你不能直接跑黑客的攻击合约,你需要输入密码,你还需要一些新的交易去补全整个攻击。

我们可以用形式化验证帮我找一个能赚钱的交易,可以在 18 秒内分析。整个攻击交易能绕过这个密码,然后补全整个攻击,通过引入更多的交易或者修改某些交易一些变量。18 秒的话其实还是比较慢,因为黑客可以不断的进步,他可能就是准备工作到真正发起攻击,他可能中间只有一秒,或者说他直接合并在一个区块中完成。

形式化验证如果太慢怎么办?我们引入一个新概念就是说我们可以用模糊测试去加速整个过程。模糊测试是一个暴力破解,启发式暴力破解的算法,它会不断的去执行程序,给这个程序喂不同的输入,然后看这个程序会不会发生一些变化。在模糊测试的过程中,我们会维护一个测试用例集,这个测试用例集保存了所有的测试用例。每一次执行,我们会随机选择一个测试用例,然后对它进行修改。修改完了之后发给程序执行,执行的过程中程序会汇报一些中间信息,比如说测试覆盖率,或者说一些 Data Flow 的数据。拿到这些数据之后,我们可以去分析交易是不是让程序的测试覆盖率增加了,或者说它的 Data flow 是很特殊的,我们就把它加入到测试用例。之后我们会再次选择测试用例,对它进行一些修改,再进行一些执行。

模糊测试的优点是它可以采用同样的形式化验证和同样的规范,它的速度更快,对于同等的任务来说,模糊测试只需要 0.002% 形式化验证的时间,它每秒可以执行几万次甚至几百万次,所以它可以在很短的时间内生成出来某一些有意思的输入。因为模糊测试是真的去执行了这个程序,它是没有假阳性的。它也可以通过大规模的分布式网络或者大量的计算资源去大量降低这个时间。对于形式化验证来说,它是没办法进行一些并行计算,或者是一些分布式计算的。模糊测试的缺点是有比较高的假阴性,因为模糊测试它说到底还是一个暴力破解的算法,它没办法就是覆盖整个程序。比如说它让输入和一个比较大的数字进行比较,我们模糊测试可能就要试无限次。复杂的条件模糊测试可能需要更长的时间,相较于形式化验证,对于这个例子的话,形式化验证很快就能解决这个问题。

我们具体怎么让模糊测试和形式化验证合作,我们就是通过一个中间的调节器让形式化验证负责一部分的程序,生成一些复杂的测试用力,然后让模糊测试负责一些简单的程序,大部分的程序还是简单的,所以我们可以直接让模糊测试负责快速生成简单测试用例。

大部分人都不会写规范,因为写规范还是要懂一点逻辑或者懂一点编程的,但是如果你就想直接去找一些套利机会的话就很难写,如果你也不是程序员的话,你也不会写这些。我们可以通过大语言模型去生成正式规范,然后再把这个规范给到形式化验证和模糊测试去生成出来一个具体交易。比如说左边这个是 ERC-20 代币,然后我想知道我是不是在未来会没法交易。我们用大语言模型帮你转换成一个正式的规范,然后这个正式规范是我们的形式化验证还是模糊测试都能执行的,然后模糊测试和形式化验证的结果,我们再贴到下面。我们同时还会用大语言模型去解释这个结果。具体来说我们将 Certora、Veridise 一些开源的规范转换为统一的语言,然后我们再进行一些人工的标注,或者直接用他们代码中的一些注释去生成一个数据集,我们用这个数据集去训练大语言模型。为了确保生成出来的规范和人想表达的意思是一样的,我们会将这个生成出来的规范再翻译回自然语言,就相当于说我先把它翻译成规范,然后再翻译回自然语言。这样我们就可以确认用户想表达的真实意思。

我们只让用户直接生成规范的话,我们单次的准确率是 67%,如果我们和用户多次确认,然后告诉用户哪里可能存在问题,哪里可能存在一些模糊问题,可以达到百分,多次确认之后可以达到 99% 的准确率。对于未调优的 GPT4 来说的话,准确率只有 1%。这就是形式化验证下大语言模型的一个应用。
免责声明:
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表Bi123的观点或立场



