英伟达的江山,还能坐多久?
Foresight · 2023-09-05 13:35
元宇宙
数据
安全
国产芯片的「算力之困」,确实撕开了一道口子。
撰文:举大名耳
当下的 AI 赛场上,英伟达无疑是最闪耀的一颗明星。
十多年来,英伟达在生产能够执行复杂 AI 任务(如图像、面部和语音识别)的芯片方面,建立了几乎无法撼动的领先地位。
然而,凡事总有变化。

近期,随着谷歌、IBM 等巨头开始在芯片方面一齐发力,GPU 领域的竞争格局,开始有了些微妙的改变。
最近,IBM 推出一款全新的 14nm 模拟 AI 芯片,效率达到了最领先 GPU 的 14 倍。
其最大的亮点,就是借助神经网络在生物大脑中运行的关键特征,来减少能耗。从而最大限度地减少人们在计算上花费的时间和精力。

同样的,身为科技巨头的谷歌,也在 8 月底的 GoogleCloudNext2023 大会上,发布了一款全新 AI 芯片 CloudTPUv5e,专为大模型训练推理所设计。
具体来说,CloudTPUv5e 允许多达 256 个芯片互连,聚合带宽超过 400Tb/s 和 100petaOps 的 INT8 性能。

根据速度基准测试,在 CloudTPUv5e 上训练和运行人工智能模型的速度提高了 5 倍。
由此可见,各大巨头其实并不甘于在算力问题上永远被英伟达「卡脖子」,并开始纷纷推出了各自的芯片,对英伟达的 GPU 霸权地位发起了「围攻」。
那么,在英伟达深不见底的护城河面前,这样的挑战前景究竟如何?
「霸主」的远虑
英伟达的江山还能坐多久?
从某种程度上说,决定这件事的,不仅仅是英伟达本身的创新能力,还有科技发展固有的定律。
作为计算机行业的黄金定律,摩尔定律一直指导着芯片开发。
但是随着芯片工艺升级速度的放缓,围绕在这一定律身上的争议也在不断扩大。
所谓摩尔定律,指的是集成电路上可以容纳的晶体管数目在大约每经过 18 个月到 24 个月便会增加一倍。
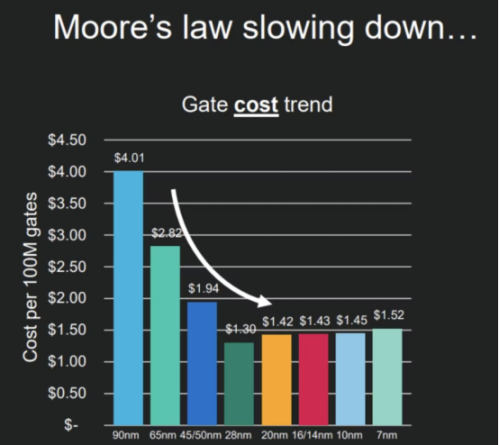
然而,随着芯片技术的不断发展,摩尔定律正逐渐遭遇瓶颈。
CIC 灼识咨询曾披露,受制于芯片尺寸的物理极限、光刻技术、隧道效应、功耗和散热、供电能力等问题,从 5nm 到 3nm 再到 2nm,其间隔都超过了 2 年时间。
面对这种情况,即使是以「刀法精湛」著称的黄仁勋,也不得不无奈地宣布「摩尔定律已死」,涨价身不由己!
其在去年发布的 AD102(RTX4090) 芯片,尺寸为 608mm,这仅比 628mm 的 GA102(RTX3090Ti)略小。
按照这样的技术路径,传统 GPU 的天花板,似乎已经越来越近。

也正因如此,各路巨头在解决算力之困的同时,也在积极地「另辟蹊径」,找到一条有别于传统路线的破局之策。
前面提到的 IBM 模仿人脑神经结构的类脑芯片,就是这样的尝试之一。
然而,在面对传统芯片瓶颈方面,业界存在着很多种不同的方案,比如量子芯片、光子芯片、类脑芯片,但如同当年 GPU 取代 CPU,成为今天 AI 计算的主力一样,在多种技术路径的博弈中,最终往往会有一个「最优」的路径胜出,成为新时代通用的芯片范式。
而这样的「最优」路径,则理应是一种在技术成熟度、通用性和市场需求等方面,都做到了较好兼顾的一种方案。

就目前的情况来看,量子芯片、光子芯片、类脑芯片等都还处于研发阶段,其技术成熟度还有待实践的检验。
此外,量子芯片、光子芯片、类脑芯片等都是针对特定的计算问题而设计的,其在通用性、兼容性上,往往还存在着一定的不足,
例如量子芯片适合解决一些经典计算机难以解决的重要问题。光子芯片适合解决一些高速数据处理和传输的问题,如光通信、光互连、光计算等。
而综合比较下来,目前最有可能胜出的方案,则是多种芯片模块组合的超异构计算。
新的赛道
什么是超异构计算?
简单来说,就像是一个拼图游戏,把不同的芯片模块(如 CPU、GPU、FPGA 等)按照不同的规则和目标来拼接,形成不同的计算方案。从而处理不同类型的数据和工作负载的技术。
超异构计算的目的是实现计算的最优化,即在性能、功耗、延迟等方面达到最佳的平衡。

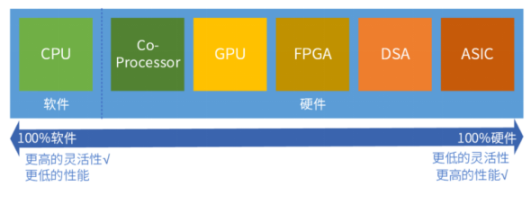
- 在 CPU 同构计算阶段,100% 工作由 CPU 完成;
- 但在 GPU 异构阶段,80% 工作由 GPU 完成,CPU 只完成剩余的 20% 的工作;
- 而在超异构计算阶段,则 80% 的工作由各类更高效的 DSA 完成,GPU 只完成剩余 20% 工作的 80%,即 16% 的工作,剩余的 4% 交给 CPU。
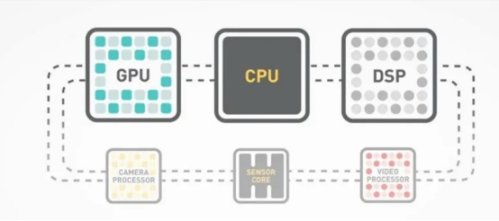
这里的 DSA,是一种针对特定领域和场景的计算单元,可以实现高效的数据处理和算法加速。例如神经网络处理器(NPU)、图形处理器(GPU)、数字信号处理器(DSP)、视觉处理器(VPU)、安全处理器(SPU)等 。
这些「术业有专攻」的特定芯片可以比传统的 GPU 更快、更省电、更小巧、更灵活。
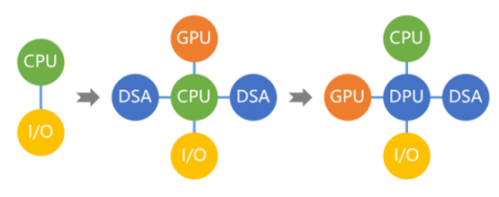
但同时,由于高度特化的 DSA 不太适合做其他方面的工作。所以,还需要用到一些 GPU 和 CPU 来辅助和协调这些芯片,完成剩下的一些计算工作。
这样,在「专人专职」的分工搭配下,芯片就可以实现计算的最优化,即在性能、功耗、延迟等方面达到最佳的平衡。
在面对 AI 大模型、自动驾驶、元宇宙等新兴的领域和应用场景时,AI 要做的事情越来越多,越来越难,而传统的同构芯片已经跟不上 AI 的步伐,难以给 AI 提供足够的算力和速度。
而超异构计算可以提供更高的灵活性和可扩展性,能够根据不同的数据和工作负载,动态地分配和调度计算资源,实现计算的自适应和智能。
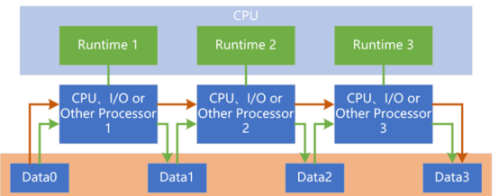
具体来说,超异构计算可以分为两种模式:静态超异构计算和动态超异构计算。
- 静态超异构计算,是指在设计阶段就确定好各个处理器之间的分工和协作方式,适用于一些稳定且可预测的场景,如视频编解码、图像处理等;
- 动态超异构计算是指在运行时根据实时数据和工作负载来动态地选择和调度最合适的处理器,适用于一些更具变化的场景,如云计算、边缘计算、物联网等;
通过这类「动静结合」的方式,超异构计算就能灵活调整负载,实现高效地算力调度。

除此之外,从成本上说,超异构计算同样是一种有效降低大算力芯片成本的方案。
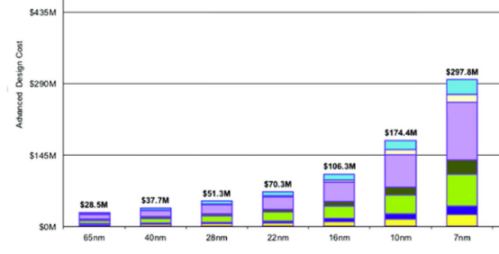
随着传统 GPU 芯片尺寸的不断缩小,人们就需要更多的研发投入和更精密的制造设备,这就导致了成本的上升。
知名半导体研究机构 Semiengingeering 统计了不同工艺下芯片所需费用,其中 7nm 节点需要的费用已经达到了 2.97 亿美元;但超异构计算,却凭借多种芯片间灵活的分工、协作,巧妙地解决了这一难题。
用一个形象的比喻来说,传统 GPU 芯片就像是一辆跑车,要想让它跑得更快,就需要不断地改进发动机、轮胎、刹车等部件,因而制造成本会成倍上升。
而超异构计算就像是一辆多功能汽车,它可以根据不同的路况和需求,切换不同的驱动模式,如越野、运输、载客等,如此一来,就不用一味地改进发动机(缩小芯片尺寸)来提高性能了。
弯道超车
正是由于这样的优势,超异构计算不仅突破了传统 GPU 的瓶颈,并且也对了国产大算力芯片提供了「弯道超车」的历史时机。
就目前来看,在超异构计算的赛道上,英伟达等巨头的布局也非常积极和全面,推出了 Hopper 超级芯片,与 GraceCPU 和 BluefieldDPU 集成,构成一个完整的超异构系统。
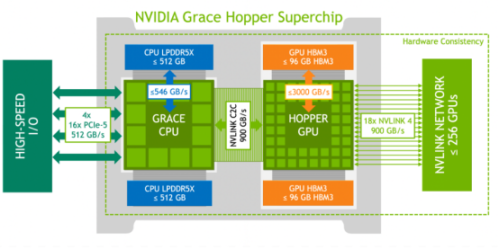
但国内厂商也同样开始在这一方向进行了发力,如华为推出了鲲鹏 920 处理器,这是一款基于 ARM 架构的高性能 CPU,可以与华为自研的昇腾 AI 芯片和昆仑 AI 芯片实现异构协同,支持云、边、端等多种场景。
还有一些国内厂商也在研发自己的超异构芯片,例如紫光展锐推出了虎贲 T7520 处理器,这是一款集成了 CPU、GPU、NPU、ISP 等多种计算单元的超异构芯片,专为 5G 终端而设计。

从总体来说,超异构计算是否会给国内芯片厂商提供弯道超车的机会,主要取决于以下几个因素:
- 国内芯片厂商在不同类型的计算单元上的技术水平和竞争力,例如 CPU、GPU、DPU、FPGA 等,以及它们之间的协同和优化能力。
- 国内芯片厂商在高速互连和先进封装方面的创新能力和成本控制能力,例如 2.5D 和 3D 堆叠技术,以及对不同工艺节点和架构的兼容性和可扩展性。
- 国内芯片厂商在统一软件平台方面的开发能力和生态建设能力,例如支持多种异构设备的编程框架和管理平台,对不同场景和应用的适配能力。
在这三个方面,目前的国内企业虽然有一定的探索和进展,但总体而言,仍面临不小的挑战。
例如,不同类型的计算单元上的技术水平上,国内仍存在着一定的短板,例如华为的鲲鹏 920 处理器虽然在性能上有所提升,但是在兼容性和生态方面还有不足。
在高速互连和先进封装方面,对于 2.5D 和 3D 堆叠等关键技术,目前国内芯片厂商还没有完全掌握,并且还依赖于国外供应商。
而目前国内厂商目前突破最大,也最具潜力的方向,是软件平台的开发能力上。
因为,超异构计算的硬件多样性和复杂性,给开发者带来了很大的挑战。
如果有一个统一的软件平台,可以屏蔽底层的细节,提供高效的编译、调度、优化等功能,那么就可以大大降低开发者的负担,提高超异构计算的可用性和普及性。
现阶段,阿里云的异构计算产品家族,包括 GPU 云服务器、FPGA 云服务器和弹性加速计算实例 EAIS 等,提供了一系列的异构计算服务和解决方案。
而华为的 Atlas 异构计算平台,基于自研的昇腾 AI 处理器,也提供了从芯片到云服务的全栈异构计算解决方案。
综合以上各种因素,以及英伟达自身的研发能力这一「动态变量」进行考虑,未来芯片市场的竞争格局,大致会呈现如下态势:
国内芯片厂商未来5 年在超异构计算上的竞争水平,会有一定程度的提升和突破,解决部分算力「卡脖子」问题,但是还无法完全摆脱对英伟达等国外巨头的依赖。
在一些特定的场景和应用上,国内芯片厂商可以与英伟达 等巨头形成有效的竞争,例如在 5G、物联网、边缘计算等领域,国内芯片厂商可能会推出更适合本地化需求和环境的超异构计算解决方案。
可以说,超异构计算,确实为国产芯片的「算力之困」撕开了一道口子,但从长远来看,要想完全解决「卡脖子」问题,并与英伟达等巨头形成对等竞争,仍是一个任重道远的过程。
免责声明:
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表Bi123的观点或立场



