深度 AIGC 技术剖析,一文看懂 3D 数据生成的历史及现状
Foresight · 2023-07-28 20:06
元宇宙
游戏
数据
AIGC 的下一个突破口。
撰文:Chengxi
编辑:蔓蔓周
过去 18 个月,AI 内容生成(AIGC)是无疑是硅谷科技创投圈内最火爆、最热门的话题。
- DALL-E(2021 年 1 月推出)
- Midjourney(2022 年 7 月推出)
- Stable Diffusion(2022 年 8 月推出)
这类 2D 生成式工具,能够在短短几秒内将文本提示(prompt)生成艺术风格的图片。随着这类 2D AIGC 工具的演化和进步,艺术家、设计师和游戏工作室的创作工作流正在被迅速颠覆革新。
AIGC 的下一个突破口在哪?不少投资者和领域资深人士都给出了预测 — 3D 数据生成。
我们注意到 3D AIGC 正在经历着 2D AIGC 曾经发展过的阶段。这篇文章中,我们将更深入地讨论 AIGC 在 3D 数据领域的新突破,以及展望生成式 AI 工具如何提高 3D 数据生成的效率和创新。
01 回顾 2D AIGC 的高速发展
2D AIGC 的发展可以简单概括为以下三个发展阶段:
第一阶段:智能图像编辑
早在 2014 年,随着生成对抗网络(GAN,典型后续工作 StyleGAN)和变分自编码器(VAE,典型后续工作 VQVAE,alignDRAW)的提出,AI 模型便开始被广泛运用到 2D 图片的智能生成与编辑中。早期的 AI 模型主要被用于学习一些相对简单的图像分布或者进行一些图像编辑,常见的应用包括:人脸生成、图像风格迁移、图像超分辨率、图像补全和可控图像编辑。
但早期的图像生成 / 编辑网络与文本的多模态交互非常有限。此外,GAN 网络通常较难训练,常遇到模式坍塌(mode collapse)和不稳定等问题,生成的数据通常多样性较差,模型容量也决定了可利用数据规模的上限;VAE 则常遇到生成的图像模糊等问题。
第二阶段:文生图模型的飞跃
随着扩散生成(diffusion)技术的突破、大规模多模态数据集(如 LAION 数据集)和多模态表征模型(如 OpenAI 发布的 CLIP 模型)的出现与发展,2D 图像生成领域在 2021 年前后取得重要进展。图像生成模型开始与文本进行深入的交互,大规模文生图模型惊艳登场。
当 OpenAI 在 2021 年初发布 DALL-E 时,AIGC 技术开始真正显现出巨大的商业潜力。DALL-E 可以从任意的文本提示中生成真实和复杂的图像,并且成功率大大提高。一年之内,大量文生图模型迅速跟进,包括 DALL-E 2(于 2022 年 4 月升级)和 Imagen(谷歌于 2022 年 5 月发布)。虽然这些技术当时还无法高效帮助艺术创作者产出能够直接投入生产的内容,但它们已经吸引了公众的注意,激发了艺术家、设计师和游戏工作室的创造力和生产潜力。
第三阶段:从惊艳到生产力
随着技术细节上的完善和工程优化上的迭代,2D AIGC 得到迅猛发展。到 2022 年下半年,Midjourney、Stable Diffusion 等模型已成为了广受欢迎的 AIGC 工具。他们通过大规模的训练数据集的驱动,使得 AIGC 技术在现实世界应用中的性能已经让媒体、广告和游戏行业的早期采用者受益。此外,大模型微调技术的出现与发展(如 ControlNet 和 LoRA)也使得人们能够根据自己的实际需求和少量训练数据来“自定义”调整、扩展 AI 大模型,更好地适应不同的具体应用(如二次元风格化、logo 生成、二维码生成等)。
现在,使用 AIGC 工具进行创意和原型设计很多情况下只需几小时甚至更短,而不是过去需要的几天或几周。虽然大多数专业的图形设计师仍然会修改或重新创建 AI 生成的草图,但个人博客或广告直接使用 AI 生成的图像的情况越来越普遍。

alignDRAW, DALL-E 2, 和 Midjourney 文本转图像的不同效果。
除了文本转图像,2D AIGC 持续有更多的最新发展。例如,Midjourney 和其他创业公司如 Runway 和 Phenaki 正在开发文本到视频的功能。此外,Zero-1-to-3 已经提出了一种从物体的单一 2D 图像生成其在不同视角下对应图片的方法。
由于游戏和机器人产业对 3D 数据的需求不断增长,目前关于 AIGC 的前沿研究正在逐渐向 3D 数据生成转移。我们预计 3D AIGC 会有类似的发展模式。
02 3D AIGC 的「DALL-E」时刻
近期在 3D 领域的种种技术突破告诉我们,3D AIGC 的“DALL-E”时刻正在到来!
从 2021 年末的 DreamFields 到 2022 年下半年的 DreamFusion 和 Magic3D,再到今年五月的 ProlificDreamer,得益于多模态领域和文生图模型的发展,学术界文生 3D 模型也得到了不少突破。不少方法都能够从输入文本生成高质量的 3D 模型。
然而这些早期探索大多数需要在生成每一个 3D 模型时,都从头优化一个 3D 表示,从而使得 3D 表示对应的各个 2D 视角都符合输入和先验模型的期待。由于这样的优化通常需要成千上万次迭代,因此通常非常耗时。例如,在 Magic3D 中生成单个 3D 网格模型可能需要长达 40 分钟,ProlificDreamer 则需要数小时。此外,3D 生成的一个巨大挑战便是 3D 模型必须具备从不同角度看物体形状的一致性。现有的 3D AIGC 方法常遇到雅努斯问题(Janus Problem),即 AI 生成的 3D 对象有多个头或者多个面。

由于 ProlificDreamer 缺乏 3D 形状一致性而出现的雅努斯问题。左边是一只看似正常的蓝鸟的正面视图。右边是一幅令人困惑的图像,描绘了一只有双面的鸟。
但另外一方面,一些团队正在尝试突破现有的基于优化的生成范式,通过单次前向预测的技术路线来生成 3D 模型,这大大提高了 3D 生成速度和准确度。这些方法包括 Point-E 和 Shap-E(分别于 2022 年和 2023 年由 OpenAI 发布)和 One-2–3–45(2023 年由加州大学圣地亚哥分校发布)。特别值得注意的是,最近一个月发布的 One-2–3–45 能够在仅 45 秒的时间内从 2D 图像生成高质量和具备一致性的 3D 网格!

对单图像到 3D 网格方法的比较分析。从左到右,我们可以观察到,处理时间从超过一个小时大幅度减少到不到一分钟。Point-E、Shap-E 和 One-2–3–45 在速度和准确性上都有出色表现。
这些 3D AIGC 领域最新的技术突破,不仅大大提高了生成速度和质量,同时让用户的输入也变得更加灵活。用户既可以通过文本提示进行输入,也可以通过信息量更加丰富的单张 2D 图像来生成想要的 3D 模型。这大大扩展了 3D AIGC 在商业应用方面的可能性。
03 AI 革新 3D 生产过程
首先,让我们了解一下传统 3D 设计师创建 3D 模型,所需要经历的工作流程:
1.概念草图:概念艺术设计师根据客户输入和视觉参考进行头脑风暴和构思所需的模型。
2.3D 原型制作:模型设计师使用专业软件创建模型的基本形状,并根据客户反馈进行迭代。
3.模型细化:将细节、颜色、纹理和动画属性(如绑定、照明等)添加到粗糙的 3D 模型中。
4.模型最终定型:设计师使用图像编辑软件增强最终的渲染效果,调整颜色,添加效果,或进行元素合成。
这个过程通常需要几周的时间,如果涉及到动画,甚至可能需要更长。然而,如果有 AI 的帮助,上述每个步骤都可能会更快。
1.强大的多视图图像生成器(例如,基于 Stable Diffusion 和 Midjourney 的 Zero-1–to–3)有助于进行创意头脑风暴,并生成多视图图像草图。
2.文本到 3D 或图像到 3D 技术(例如,One-2–3–45 或 Shap-E)可以在几分钟内生成多个 3D 原型,为设计师提供了广泛的选择空间。
3.利用 3D 模型优化(例如,Magic 3D 或 ProlificDreamer),选定的原型可以在几小时内自动进行精炼。
4.一旦精炼的模型准备好,3D 设计师就可以进一步设计并完成高保真模型。
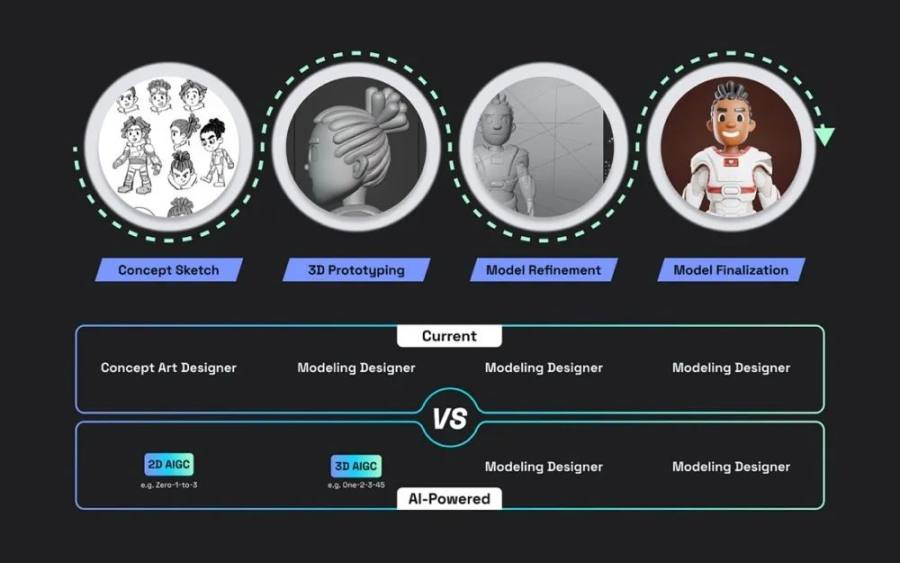
传统与 AI 驱动的 3D 生产工作流程对比
04 3D AIGC 是否会取代人类?
我们的结论是,暂时不会。人仍然是 3D AIGC 环节中不可缺失的一环。
尽管以上提到的 3D 模型生成技术,能在机器人技术、自动驾驶和 3D 游戏中有许多应用,然而目前的生产流程仍然不能满足广泛的应用。
为此,硅兔君采访了来自加州大学圣迭戈分校的苏昊教授,他是 3D 深度学习(3D Deep Learning)和具身人工智能(Embodied AI)领域的领军专家,也是 One-2–3–45 模型的作者之一。苏昊教授认为,目前 3D 生成模型的主要瓶颈是缺乏大量高质量的 3D 数据集。目前常用的 3D 数据集如 ShapeNet(约 52K 3D 网格)或 Objaverse(约 800K 3D 模型)包含的模型数量和细节质量都有待提升。尤其是比起 2D 领域的大数据集(例如,LAION-5B),它们的数据量仍然远不够来训练 3D 大模型。
苏昊教授曾师从几何计算的先驱、美国三院院士Leonidas Guibas 教授,并曾作为早期贡献者参与了李飞飞教授领导的 ImageNet 项目。受到他们的启发,苏昊教授强调广泛的 3D 数据集在推进技术方面的关键作用,为 3D 深度学习领域的出现和繁荣做出了奠基性工作。
此外,3D 模型远比 2D 图像的复杂很多,例如:
1.部件结构:游戏或数字孪生应用需要 3D 对象的结构化部件(例如,PartNet),而不是单一的 3D 网格;
2.关节和绑定:与 3D 对象互动的关键属性;
3.纹理和材料:例如反光率、表面摩擦系数、密度分布、杨氏模量等支持交互的关键性质;
4.操作和操控:让设计师能够对 3D 模型进行更有效地交互和操纵。
而以上几点,就是人类专业知识能够继续发挥重要作用的地方。
苏昊教授认为,在未来,AI 驱动的 3D 数据生成应具有以下特性:
1.支持生成支撑交互性应用的 3D 模型,这种交互既包括物体与物体的物理交互(如碰撞),也包括人与物体的交互(物理与非物理的交互方式),使得 3D 数据在游戏、元宇宙、物理仿真等场景下能够被广泛应用;
2.支持 AI 辅助的 3D 内容生成,使得建模的生产效率更高;
3.支持 Human-in-the-loop 的创作过程,利用人类艺术天赋提升生成数据的质量,从而进一步提升建模性能,形成闭环的数据飞轮效应。
类似于过去 18 个月来像 DALL-E 和 ChatGPT 这样的技术所取得的惊人发展,我们坚信在 3D AIGC 领域即将发生,其创新和应用极有可能会超过我们的预期,硅兔君会持续深入探索和输出。
免责声明:
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表Bi123的观点或立场
热点



