全同态加密如何解决 LLM 的隐私问题
Foresight · 2023-10-18 14:50
隐私
数据
安全
全同态加密的安全性和大语言模型的计算能力的结合可以重新定义人工智能交互,确保效率和隐私两者兼顾。
撰文:Ingonyama
人工智能的崛起令人惊叹。从基本的算法,到如 ChatGPT 和 Copilot 这样的语言学习模型 (LLMs),人工智能已处于技术演进的前沿。随着这些模型与用户互动并处理大量数据和提示,数据隐私问题变得尤为重要。其中亚马逊和苹果等大公司已经限制员工访问 ChatGPT 等公共 API,来防止可能因 AI 交互而导致的数据泄露。此外,可以合理地预测,相关法规将很快出台,以强制要求一定程度的用户隐私保护。
我们如何确保与这些模型的交互、提问和共享的数据保持隐私呢?
全同态加密(FHE)简介
在密码学领域,全同态加密是一个开创性的概念。它的魅力在于其拥有的一种独特能力:它允许直接对加密的数据进行计算,而不需要先对数据解密,从而实现了对敏感信息的隐私推理。
借助这种特性可以确保两个重要的事情:数据在处理过程中保持安全,以及对模型知识产权(IP)的完全保护。
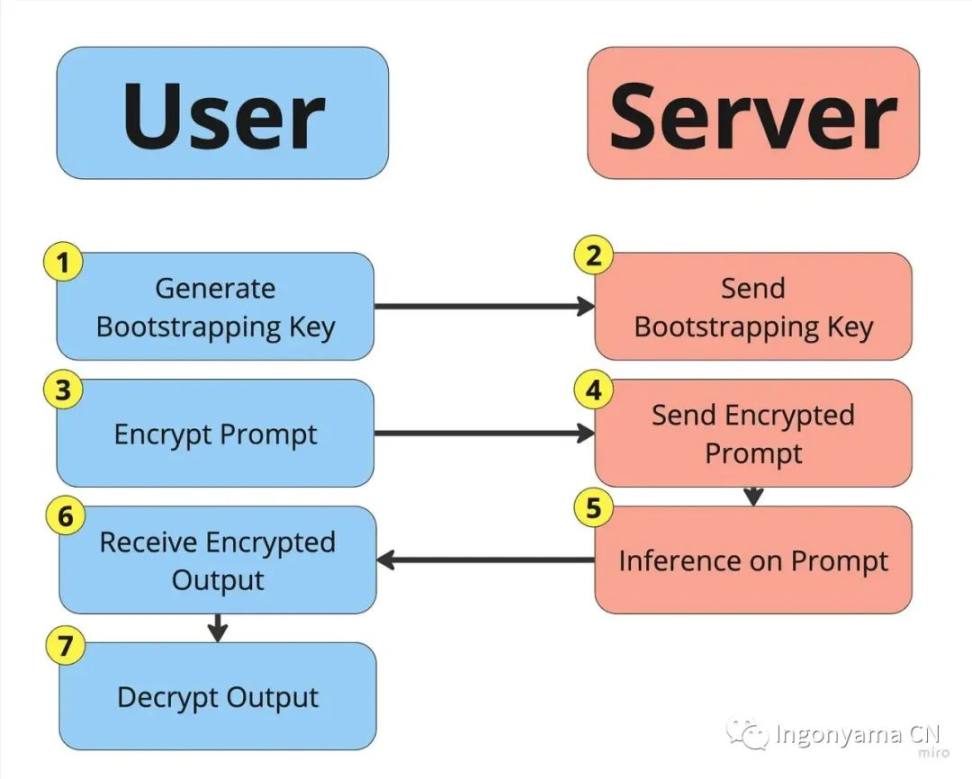
隐私推理与知识产权保护
如今,「隐私」和「用户体验」似乎是鱼和熊掌的关系,二者不可得兼。人们往往为了更好的用户体验,信任第三方去处理他们的信息。我们相信,这些第三方公司能够在用户隐私与优质的用户服务之间找到一个平衡点,而不必在隐私性更高但缺少功能的本地解决方案或牺牲隐私以获得丰富功能的服务之间做出选择。
全同态加密能够在完全保护模型知识产权的情况下实现隐私推理。通过对加密数据进行计算,它可以确保提示词完全保密,同时还能保护大语言模型的知识产权。
传统加密方法 VS FHE
在传统的加密方案中,如果要对加密形式下的数据进行有意义的运算,首先需要对其进行解密。但是解密就会暴露数据明文,这意味着数据将变得脆弱,易受到攻击,哪怕只是一瞬间的解密。
相比之下,全同态加密可以直接对密文进行运算,确保敏感信息在整个运算过程中处于「不可见」的状态。
为什么 FHE 很重要
全同态加密的重要性不仅限于理论。想象一下在云计算服务中,可以在不解密数据的情况下进行数据处理,或者医疗数据库可以在不获取敏感患者详细信息的情况下进行分析。全同态加密的潜在应用非常广泛且多样化,包括安全投票系统和对加密数据库进行隐私搜索等
FHE 的数学基础
全同态加密基于容错学习(LWE)问题,这是一种格密码学技术,具有抗量子性。在 LWE 中,利用随机噪声使数据变得不可读,除非拥有密钥。对加密数据进行算术运算是可能的,但这通常会增加噪声水平。如果连续进行过多的运算,任何人都无法读取数据,包括持有密钥的人。这就是部分同态加密(SHE)。
而要将部分同态加密转换为全同态加密,需要一种能降低噪音水平的操作。这种操作被称为「自举」(Bootstrapping),多种全同态加密方案都采用了自举操作。在本文中,我们将重点讨论环面上的全同态加密方案 (Torus FHE),它利用数学环面的代数结构来实现全同态加密。
TFHE 的优点
尽管每种全同态加密方案都有自己的优缺点,但在实际场景中,TFHE 目前拥有更高效的实现。TFHE 的另一个重要优势在于其可编程自举(Programmable Bootstrapping,PBS),它将通常的自举操作扩展到包括对单变量函数的计算,例如在机器学习领域中至关重要的激活函数。
TFHE 的一个劣势是在计算中每执行一次算术运算都需要执行一次 PBS 操作,而其他方案则允许在自举操作之间批量执行一些操作。
假设与近似
为了估计使用全同态加密进行大语言模型 (LLM) 推理所需的时间,我们做出一些假设来评估:
- 每个 Token 所需的算术操作次数大约是模型中参数数量的 1–2 倍。这是一个下限,因为每个 Token 都使用了整个模型,我们将假设这个下限足够接近实际需求。
- 大语言模型中的每个算术操作都可以映射到 TFHE 中的一个算术操作。这基本上是两种方案中变量类型大小的说明。我们假设对于大语言模型来说,INT4 变量足够,并且对于 TFHE 来说是可行的。
- 大语言模型中的每个算术操作都需要映射到全同态加密中的一个算术操作。这意味着我们不能在未加密的情况下运行模型的一部分。Zama 最近的一篇博文考虑了不使用这个假设的 FHE 推理,其中大部分模型由用户在本地执行,没有任何加密,只有一个小部分(例如单个注意力头)在模型的公司服务器上使用全同态加密运行。我们认为,这种方法实际上并没有保护模型的知识产权,因为在这种情况下,用户可以只运行缺失的头部,并且只有轻微的精度损失,如此处所示,或者对缺失部分进行相对廉价的训练,以获得与原始模型相当的结果。
- TFHE 中的每个算术操作都需要进行一次 PBS(可编程自举)。PBS 是 TFHE 计算的主要瓶颈。
- 目前最先进的 TFHE 实现是 FPT。这是一种 FPGA 实现,以每 35 微秒计算一次 PBS。
LLM 和 FHE 的挑战
随着最新技术的进展,目前最好的全同态加密实现可以在仅需 35 微秒的时间内执行一次算术操作。然而,当考虑到像 GPT2 这样复杂的模型时,单个 Token 需要进行惊人的 15 亿次操作。这意味着每个 Token 的处理时间约为 52,000 秒。
为了更好地理解,对于语言模型来说,一个 Token 可以表示一个字符或一个完整的单词等内容。想象一下与一个语言模型进行交互,其中响应时间需要一两个星期!这是不可接受的,这样的延迟显然对于实时通信或模型的任何实际应用都是不可行的。
这显示了在当前的全同态加密技术下,对于大规模的语言模型来说,实现实时推理仍然是一个巨大的挑战。尽管全同态加密在数据保护方面具有重要意义,但在需要高度计算密集型的任务中,其性能限制可能使其难以应用于实际场景。对于实时交互和快速响应的需求,可能需要探索其他的安全计算和隐私保护解决方案。
潜在的解决方案
为了使全同态加密应用到大语言模型中,以下是一个可能的路线图:
使用多机器实现并行处理:
- 起始为 52,000 秒 /Token。
- 通过部署 10,000 个并行机器,我们将时间缩短到 5 秒 /Token。请注意,大语言模型确实可以高度并行化,目前的推理通常在数千个或更多的 GPU 核心上并行执行。
过渡到先进的硬件:
- 从改进后的 -- 起始为 5 秒 /Token
- 切换到 GPU 或 ASIC,我们可以实现每个 Token 0.1 秒的处理时间。虽然 GPU 可以在速度上提供更直接的收益,但 ASIC 在速度和功耗方面都可以提供更高的收益,例如之前 Blog 提到的 ZPU 就是这样的例子。
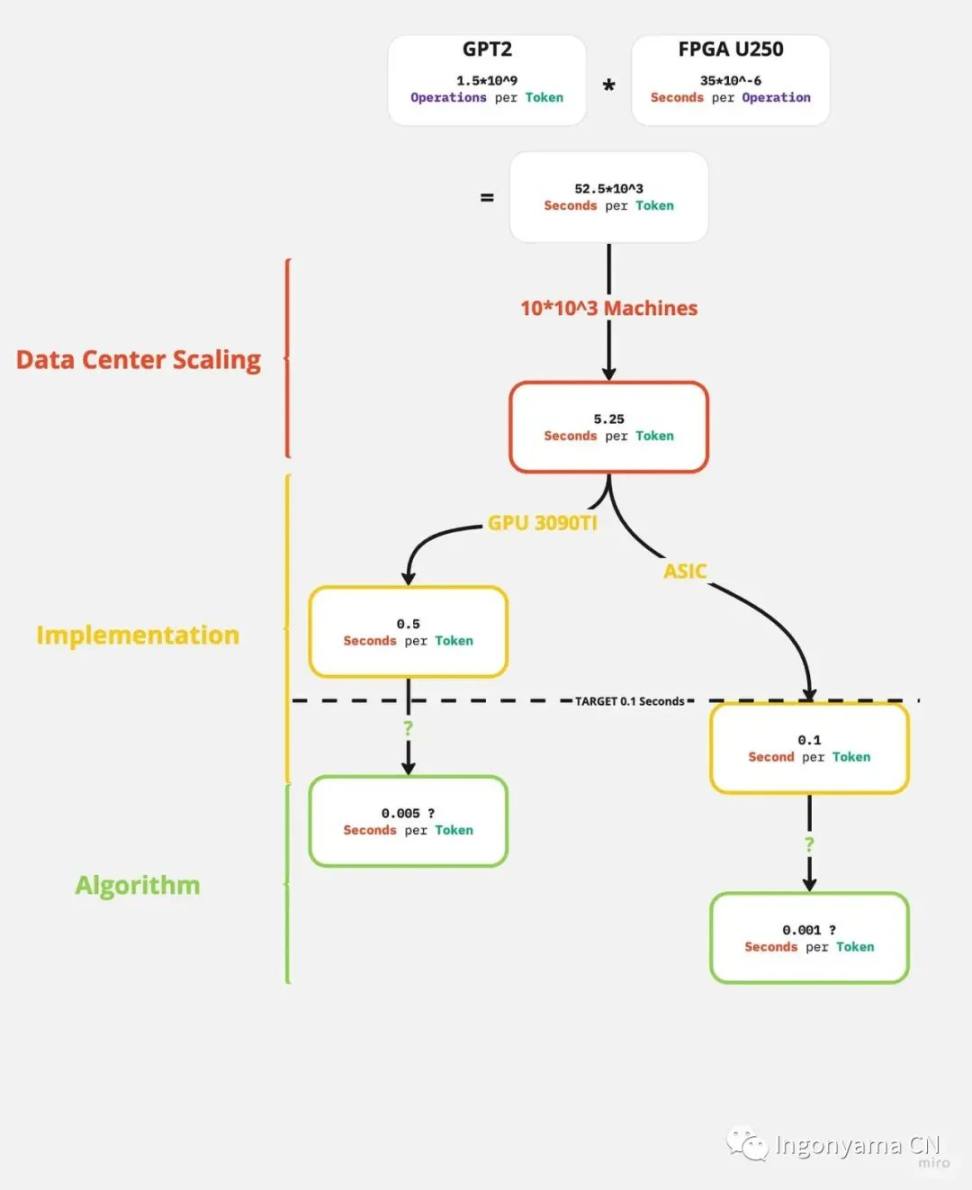
正如图所示,使用现有的数据加速技术,通过全同态加密可以实现大语言模型的私有推理。通过在足够大的数据中心中进行大规模但可行的初始投资,可以支持这一点。然而,这种可能性仍然是微乎极微的,并且对于更大的大语言模型,如 Copilot(120 亿参数)或 GPT3(1750 亿参数),仍存在差距需要弥补。
对于 Copilot 来说,较小的 Token 吞吐量就足够了,因为它生成的是代码输出,通常比人类语言更简洁。如果我们将吞吐量要求降低 8 倍,那么 Copilot 也能达到可行性的目标。
最后的差距可以通过组合更大规模的并行化、更好的实现以及在全同态加密中进行引导的更高效算法来弥补。在 Ingonyama,我们相信算法是弥合这一差距的重要组成部分,我们的团队目前正专注于相关算法的研究和开发。
总结
全同态加密的安全性和大语言模型的计算能力的结合可以重新定义人工智能交互,确保效率和隐私两者兼顾。虽然存在一些挑战,但通过持续的研究和创新,我们可以实现与 AI 模型(如 ChatGPT)的交互既具有即时性又具有隐私性的未来。这将为用户提供更高效和安全的体验,并推动人工智能技术在各个领域的广泛应用。
免责声明:
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表Bi123的观点或立场



