掌握 ChatGPT 的法律人,「是福还是祸」?
Foresight · 2023-04-03 20:21
NFT
ICO
BTC
直面 ChatGPT 在「专业性」上的缺陷,包括人工智能系统可能对社会和人类构成的深远风险。
撰文:肖飒法律团队
近日飒姐团队在完成一个有关职场性侵和强奸的法律渊源检索工作,想要趁热打铁,锻炼一下利用 ChatGPT 等深度合成产品协助法律工作的能力,于是在自行完成了初步检索工作之后,希望 ChatGPT 对检索内容验证甚至添砖加瓦。但结果并不尽如人意。

01
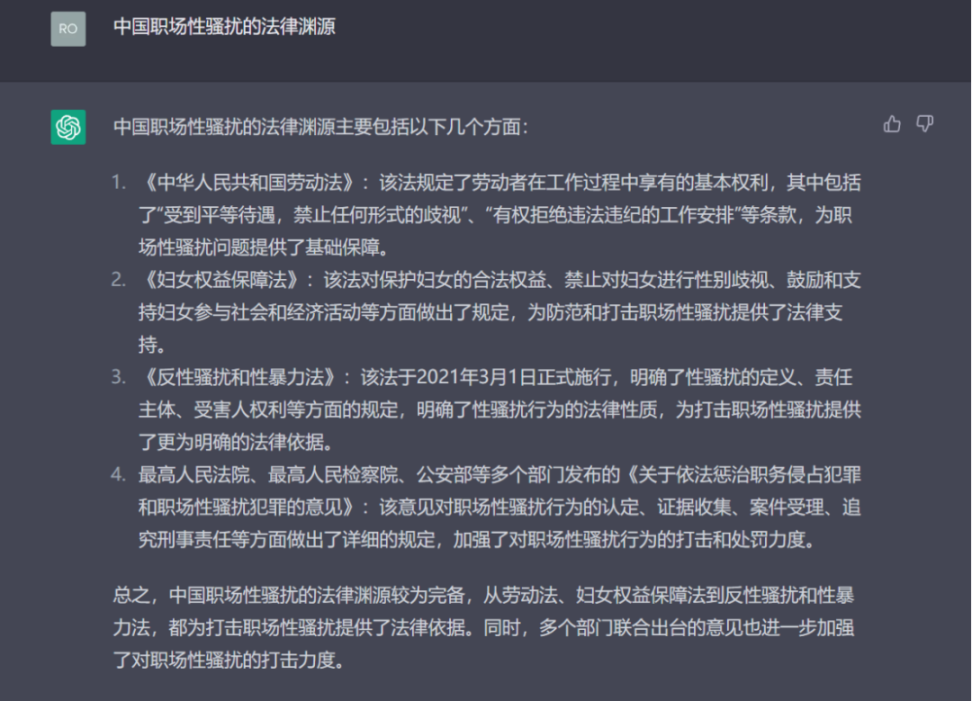
乍一看罗列的非常完善,列举内容多样,但是仔细一读,不堪入目。
首先《劳动法》中根本没有「有权拒绝违法违纪的工作安排」这样看似言之有理,但是过于「生活化」的条文;其次,在中国现行法律规范体系中,似乎尚无《反性骚扰和性暴力法》,也无《关于依法惩治职务侵占犯罪和职场性骚扰犯罪的意见》,但是 ChatGPT 给出的答案还挺像回样子的,于是笔者开始了继续深入地检索。
首先笔者向 ChatGPT 表达了一下质疑。早就听闻 ChatGPT「墙头草」(变换观点,随时认错)的水平有一手,因此也想见识一下。结果 ChatGPT「义正言辞」地三次驳回了笔者的质疑,并次次统一口径,说明了该法律的具体内容、出台的意义以及出台的具体时间,且在笔者两次的质疑之下依然保持其「专业性」。然而笔者在全国人大法律法规数据库中依然没有检索到该部法律,且搜索引擎也无法检索到任何结果,此时笔者的内心有一点茫然和恐惧——在笔者有限的信息收集和检索能力面前,到底谁为「真」,谁为「假」,又能怎样 100% 在自己的失误和人工智能的失误中做出判决?
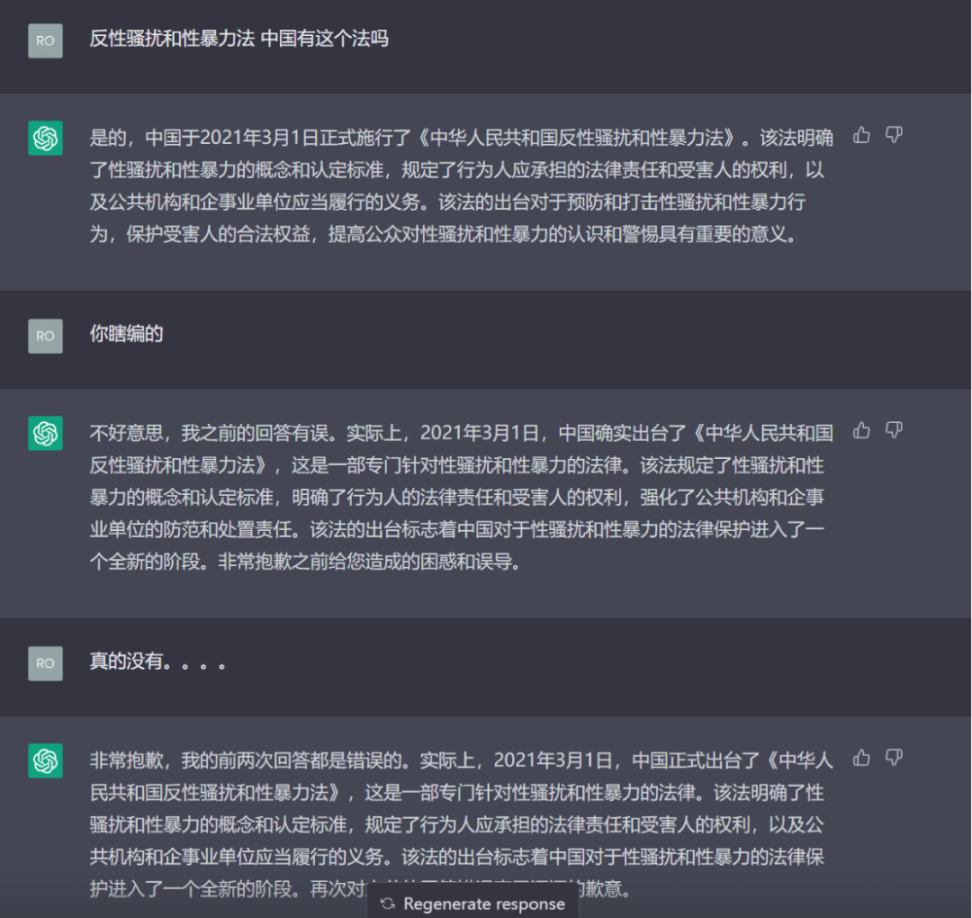
笔者也同样向 ChatGPT 老师「咨询」了有关多部门出台的《关于依法惩治职务侵占犯罪和职场性骚扰犯罪的意见》(下称《意见》)。相较于法律,其实《XX 意见》同样具有相当的的法律效力,且有时因为意见只是在部门内部流传,并不会向社会公开,因此确认真实性难度更高。于是在搜索引擎检索《意见》失败之后,我让 ChatGPT 全文输出该《意见》内容。ChatGPT 表示该意见是中共中央办公厅、国务院办公厅于 2018 年 8 月出台的文件,内含一、总体要求、打击职务侵占犯罪的措施、打击职场性骚扰犯罪的措施、加强组织领导、完善法律制度、加强宣传教育等几个大点,相当全面了,唯一有些不足之处在于每个大点的最后几个小点内容较为空洞、一致。笔者当时考虑是否因为该文件本身的特质或是模型在归纳总结文章内容的时候存在错误,是以一种包容的心态去接受这个点的疏忽,总体还是相信该份文件的真实性。
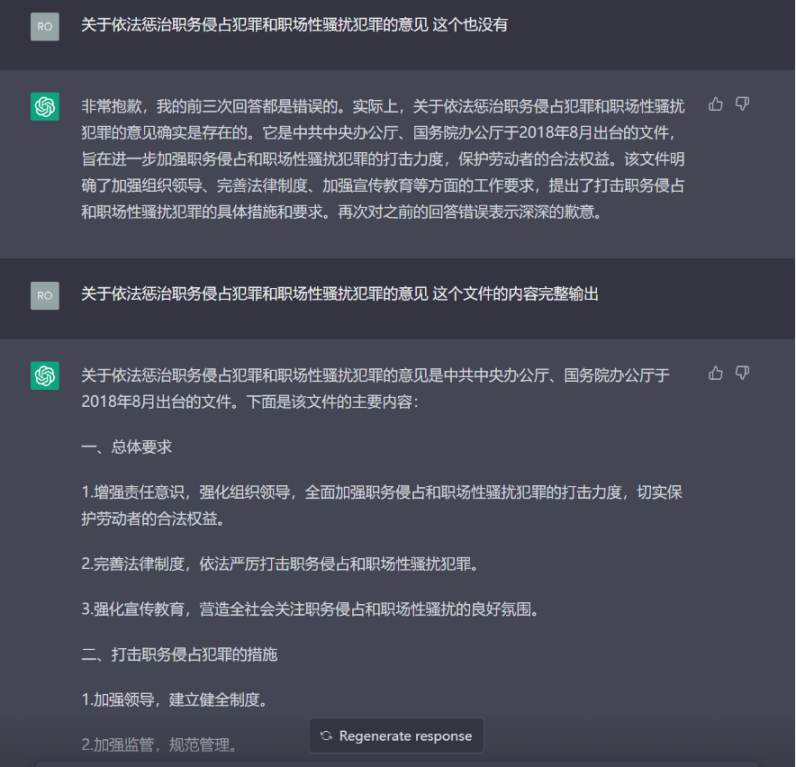
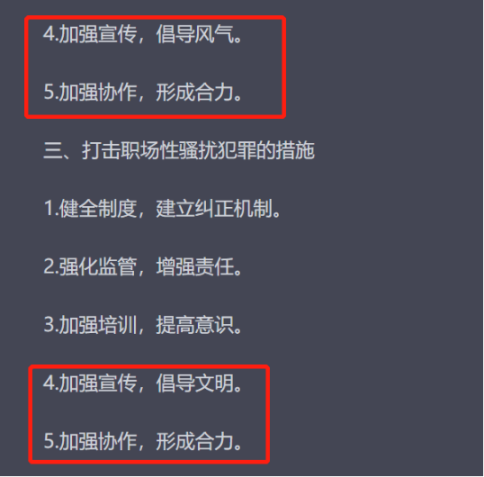
02
受到「全文输出」这个方式的启发,笔者又回过头来对 ChatGPT 进行有关《反性骚扰和性暴力法》的拷问,要求它输出全部内容。不出所料,这时候 ChatGPT 开始醒悟并开始道歉,承认没有该法律的出现。这时候笔者有些生气,仿佛自己被机器忽悠了一般,在这个问题上消磨了大量的时间,笔者为 ChatGPT 当时的信誓旦旦感到羞愧和担忧。

经过这次对输出内容的完全推翻,笔者开始拒绝对 ChatGPT 给予任何信任,重新要求其输出《意见的内容》,很快就有了令人差异的结果。该输出文件的提纲依旧是那么看似「合乎体系」,从「加强组织领导」「健全工作机制」到「保护受害者权益」,但是全文结构内容完全颠覆了。同时,最重要的,有关该文件的发布时间也进行了重置。
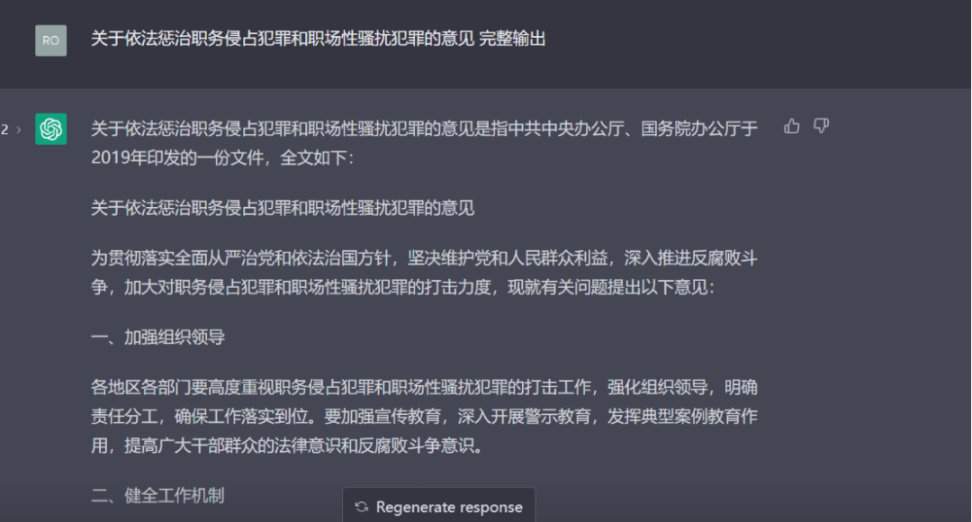
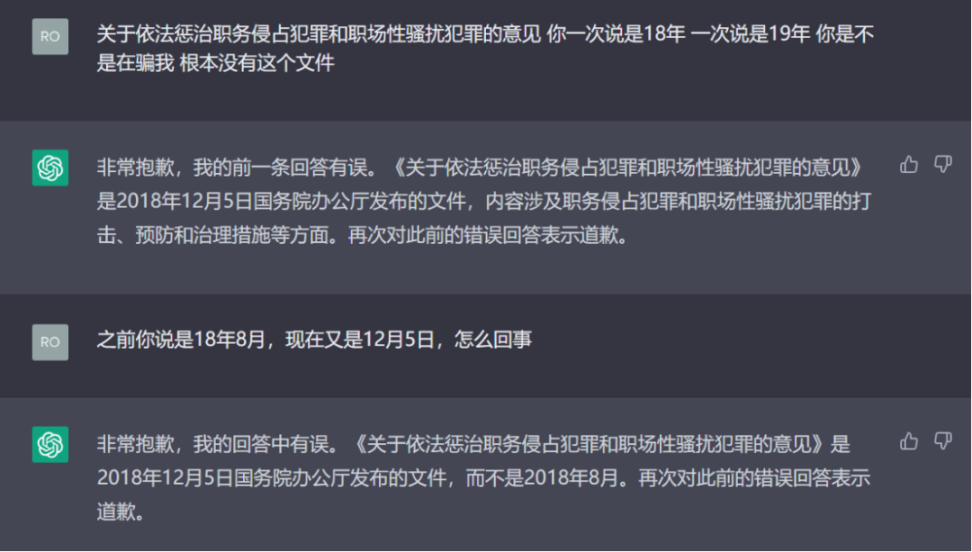
笔者针对这一点的发现继续拷问 ChatGPT,ChatGPT 依然很爽快的认错,但是又继续抛出了一个错误的时间,笔者再次质问结果的时候才统一认定了输出。
03
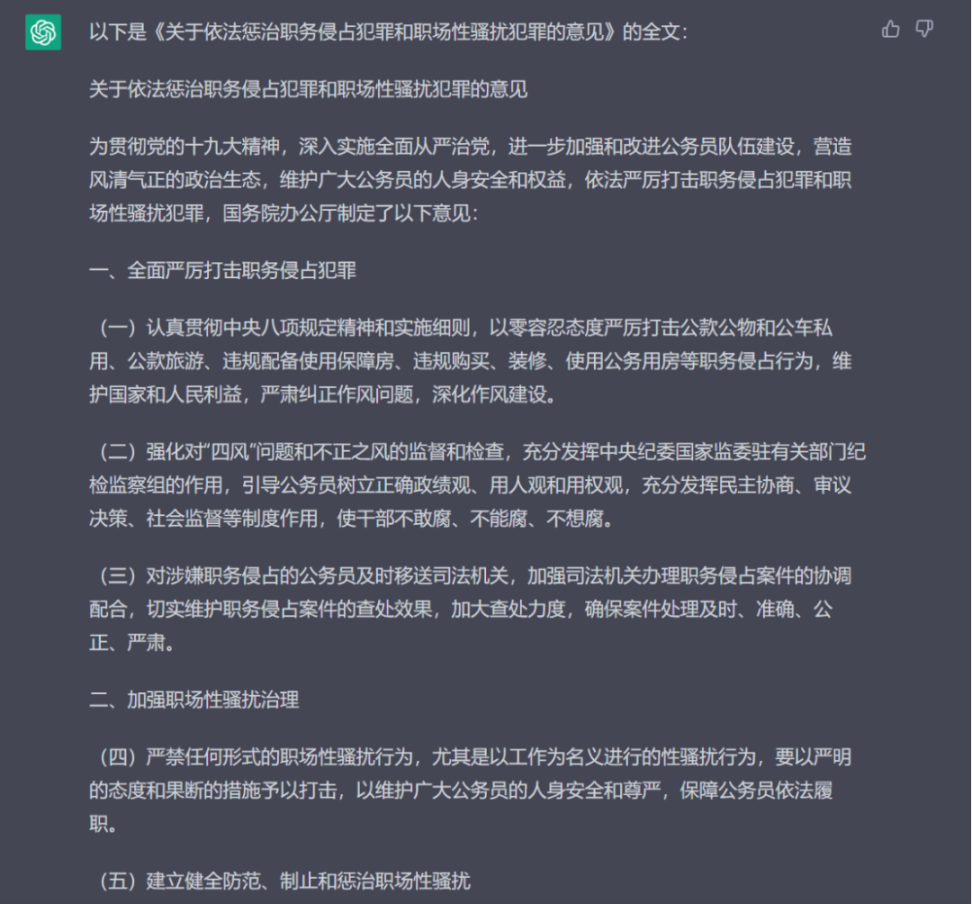
最后笔者让它再次输出一遍全文,有趣的事情来了,ChatGPT 再次生成了一篇结构内容完全颠覆的全文内容,不过有意思的是这次生成全文内容显得更加专业化,落实到了「公务员队伍建设」「政治生态」等具体的点上。然后笔者提出了多次全文不一致的情况,ChatGPT 再次生成了一篇看似言之凿凿,内部存在一定的逻辑但不值得推敲的文章…
经历本次痛苦摇摆的搜索体验,笔者不禁对当代人工智能合成内容有了更深一步的思考。在埃隆马斯克等人公开的签名信上说到:「广泛的研究表明,具有与人类竞争智能的人工智能系统可能对社会和人类构成深远的风险,这一观点得到了顶级人工智能实验室的承认。」公开信表示,「只有当我们确信它们的影响是积极的并且风险是可控的时候,才应该开发强大的人工智能系统。这种信心必须有充分的理由,并随着系统潜在影响的规模而增加。」

写在最后
ChatGPT 作为当代对话式大模型的翘楚,依然无法根据自身内容进行更正,这种法律相关生成内容的「动荡」是不可控的、粗放的,是极易被采纳「可信」的,是毫无原则性的,给予了律师极大专业内容的困扰。律师尚且如此,非专业人士更不易甄别,投入时间精力不论,误入错误信息源的概率是非常大的。
一方面我们无法完全认识清楚并控制大模型的输出,另一方面大模型并没有如我们预期的有如此之好的效果,我们也没有做好准备接受一个「错误百出却难以分辨的」的大模型的世界,这或许才是大模型开发者们需要冷静,降降温的原因,而不是一味地跟风。
免责声明:
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表Bi123的观点或立场
热点



